Nvidia Toolkits for Computer Vision
In this Blog we will go through the essential toolkits from Nvidia to boost performance and accuracy of Conversational AI applications.These toolkits helps you to create and deploy end to end AI pipelines. We will cover TensorRT and TAO which are used for Training custom AI models, Optimizing them to reach real time inferences as well as creating multi channel pipeline and deploying all in one application.
TensorRT
TensorRT can optimize and deploy applications to the data center, as well as embedded and automotive environments. It powers key NVIDIA solutions such as NVIDIA TAO, NVIDIA DRIVE™, NVIDIA Clara™, and NVIDIA Jetpack™.
TensorRT is also integrated with application-specific SDKs, such as NVIDIA DeepStream, NVIDIA Riva, NVIDIA Merlin™, NVIDIA Maxine™, NVIDIA Modulus, NVIDIA Morpheus, and Broadcast Engine to provide developers with a unified path to deploy intelligent video analytics, speech AI, recommender systems, video conference, AI based cybersecurity, and streaming apps in production.

This block contains unexpected or invalid content.
Attempt Block Recovery
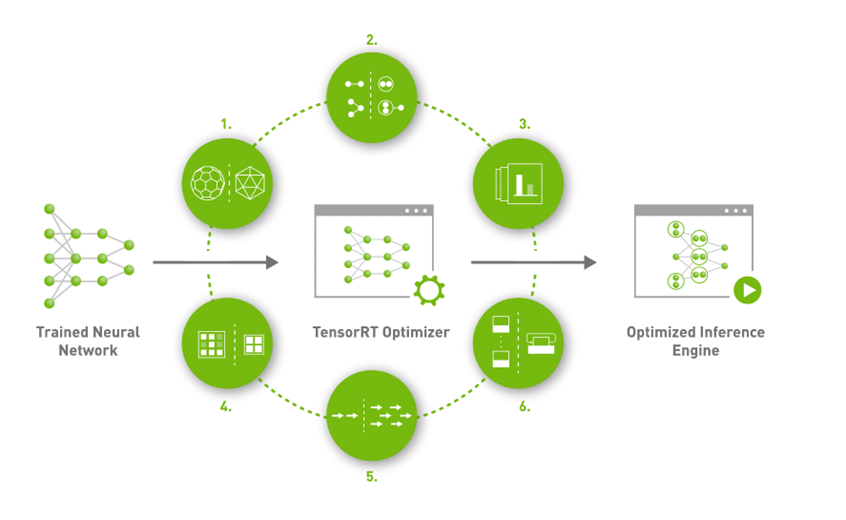
As you can see in the picture above we have 6 main steps in TensorRT Optimizer.We will mention each of them below.
1- Reduced Precision:
Maximizes throughput with FP16 or INT8 by quantizing models while preserving accuracy
2- Layer and Tensor Fusion:
Optimizes use of GPU memory and bandwidth by fusing nodes in a kernel
3- Kernel Auto-Tuning:
Selects best data layers and algorithms based on the target GPU platform
4- Dynamic Tensor Memory:
Minimizes memory footprint and reuses memory for tensors efficiently
5- Multi-Stream Execution:
Uses a scalable design to process multiple input streams in parallel
6- Time Fusion:
Optimizes recurrent neural networks over time steps with dynamically generated kernels
Nvidia TAO
Creating an AI/machine learning model from scratch can cost you a lot of time and money. Transfer learning is a popular technique that can be used to extract learned features from an existing neural network model to a new one. The NVIDIA TAO Toolkit is a CLI and Jupyter notebook based solution of NVIDIA TAO, that abstracts away the AI/deep learning framework complexity, letting you fine-tune on high-quality NVIDIA pre-trained AI models with only a fraction of the data compared to training from scratch.
The TAO Toolkit also supports 100+ permutations of NVIDIA-optimized model architectures and backbones such as EfficientNet, YOLOv3/v4, RetinaNet, FasterRCNN, UNET, and many more.
This block contains unexpected or invalid content.
Attempt Block Recovery
Edit Post “Nvidia Toolkits for Computer Vision” ‹ test — WordPress

Faster Inference Using Model Pruning & Quantization-Aware Training
Companies building AI solutions are in need of highly accurate AI models that can efficiently make predictions while achieving faster inference within tight memory constraints. Unpruned AI models, in many computer vision use-cases, are not optimized for low power devices. If you are solving a problem with a limited dataset, transfer learning along with select pruning improves channel density for high throughput inference.
Quantization-Aware Training (QAT) lets you achieve up to 2X inference speedup using INT8 precision while maintaining accuracy comparable to FP16. With QAT, the quantization of weights in the training step helps produce comparable accuracy as FP16/FP32 models, making them highly efficient for inference versus post-training quantization.
Build end-to-end services and solutions for transforming pixels and sensor data to actionable insights using DeepStream SDK and TAO Toolkit. The production ready AI models produced by TAO Toolkit can be easily integrated with NVIDIA DeepStream SDK and TensorRT for high throughput inference and enabling you to unlock greater performance for a variety of applications including smart cities and hospitals, industrial inspection, logistics, traffic monitoring, retail analytics etc.